Top 5 Common Machine Learning Mistakes Beginners Do
In this article I showcase the different ways beginners can do mistakes with Machine Learning.
Machine learning has become an essential tool in data science, but it's surprisingly easy to make fundamental mistakes that can severely impact your model's performance. In fact my motivation for this blog came out of peers underestimating the complexities of Linear Regression as a way to model data. In this guide, we'll explore the most common pitfalls and how to avoid them.
1. The "Just Throw It Into a Model" Syndrome
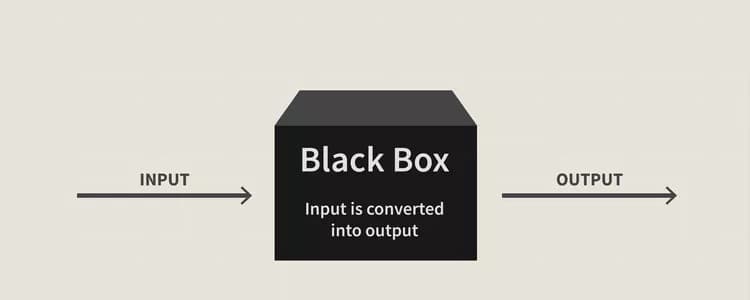
One of the most prevalent mistakes is treating machine learning like a magic black box. Many newcomers simply load their dataset into scikit-learn's LinearRegression() and expect meaningful results. This approach ignores crucial preprocessing steps and can lead to severely underperforming models.
Key Problems:
No train-test split
Missing data preprocessing
Lack of feature engineering
Ignoring data leakage
2. Data Preprocessing Oversights
Feature Scaling
Not normalizing or standardizing features is a common oversight that can significantly impact model performance. Different scales across features can cause:
Gradient descent algorithms to converge slowly
Some features to dominate others unnecessarily
Poor performance in distance-based algorithms like k-NN

Dimensionality Issues
Many practitioners fail to address the curse of dimensionality. High-dimensional data often needs:
Principal Component Analysis (PCA)
Feature selection methods
Other dimensionality reduction techniques
3. Evaluation Metric Mismatches
Choosing the wrong evaluation metric is like using a ruler to measure weight. Different problems require different metrics:
Classification Metrics
Imbalanced Data: Using accuracy for imbalanced datasets can be misleading
False Positives vs. False Negatives: Not considering the business impact of different types of errors
Common Solutions:
F1-score for balanced precision and recall
Area Under ROC Curve (AUC-ROC)
Precision for minimizing false positives
Recall for minimizing false negatives

4. Validation Vulnerabilities
Cross-Validation Mistakes
Simple train-test splits aren't enough. Common issues include:
Not using k-fold cross-validation
Applying cross-validation incorrectly
Ignoring temporal aspects in time-series data
Data Leakage
Subtle forms of data leakage can creep in through:
Preprocessing before splitting the data
Using future information in time-series
Including target-related features

5. Overcomplicating Solutions
Sometimes simpler is better. Common overcomplications include:
Using deep learning when linear regression would suffice
Adding unnecessary features without validation
Over-tuning hyperparameters without significant gains
Best Practices Checklist
Start with data exploration and visualization (EDA)
Implement proper train-test splits
Apply appropriate preprocessing techniques
Choose metrics based on business objectives
Use cross-validation for robust evaluation
Monitor for data leakage
Start simple and iterate based on results
Conclusion
Avoiding these common mistakes can significantly improve your machine learning models' performance. Remember that machine learning is not about throwing data at algorithms – it's about understanding your data, choosing appropriate methods, and carefully validating your results.
Would you like to build better models? Start by auditing your current practices against these common pitfalls. Your future self (and your models) will thank you.
P.S. Let's Build Something Cool Together!
As a versatile data professional, I have expertise in both data engineering (most recent job exp) and data science (my undergrad), including machine learning, AI. I'd be excited to collaborate on an interesting project that leverages my diverse skillset.
Also, I do a little bit of Next.JS on the side 😉.
Connect with me on Linkedin, and let's discuss potential opportunities.