Self-Learning AI: Does Reinforcement Learning Really Eliminate Data Engineering?

Picture a machine learning model that learns like a child, through trial and error, with no need for massive pre-existing datasets. That's the allure of reinforcement learning (RL), a branch of artificial intelligence that's revolutionizing everything from game-playing robots to industrial automation. While it's true that RL agents generate their own training data through interaction, the popular belief that this eliminates the need for data engineering might be too good to be true. Let's dive into the reality of data engineering in reinforcement learning and uncover whether this compelling promise holds up in practice.
The Case for Reduced Data Engineering in RL
Self-Generating Data Through Interaction
One of the most compelling arguments for reduced data engineering in RL is its ability to generate training data through direct interaction with environments. Unlike traditional supervised learning approaches, where data must be collected, cleaned, and labeled beforehand, RL agents learn through experience, creating their own training examples along the way.
The Power of the Reward Signal
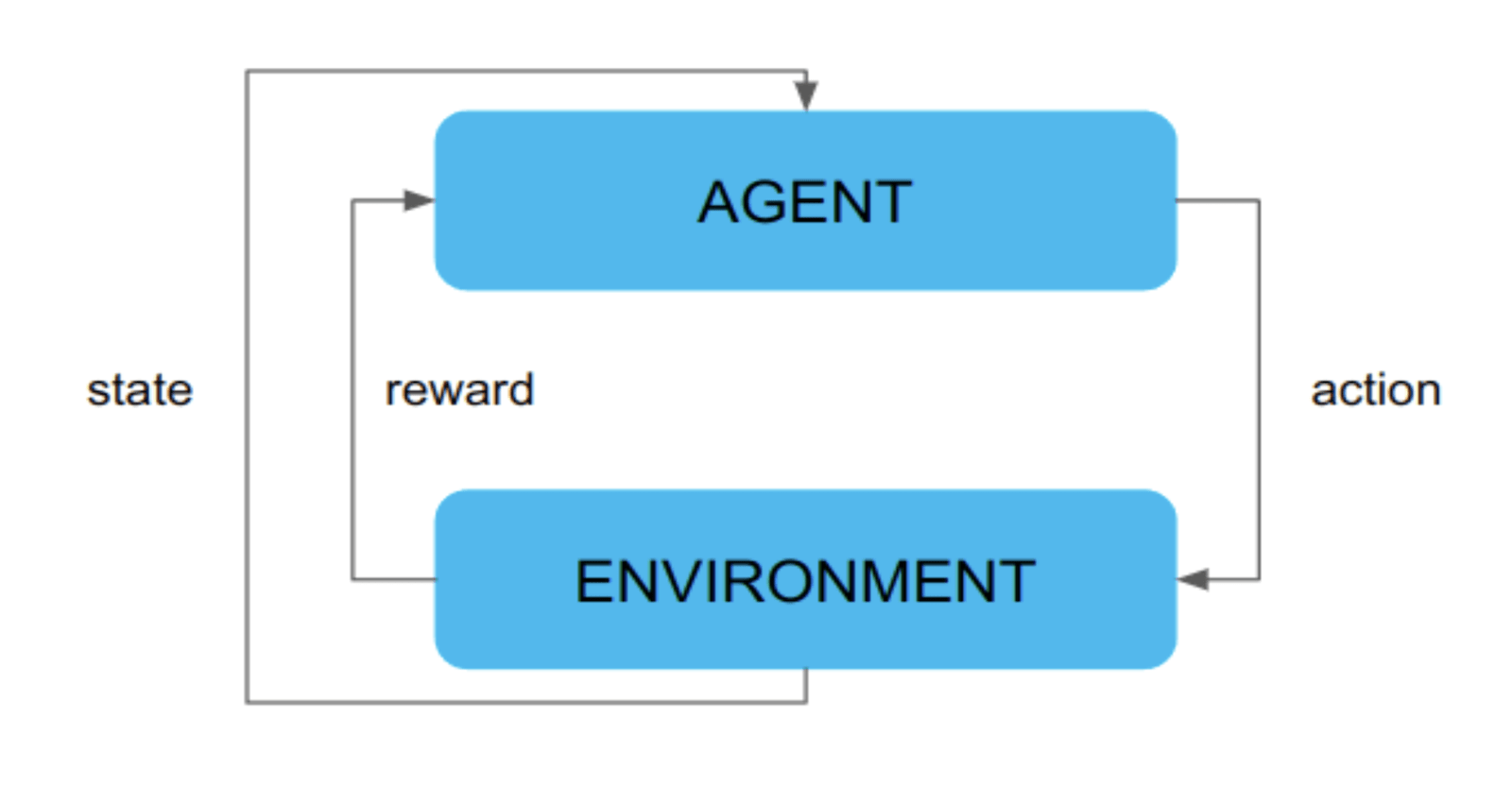
Reinforcement learning's reliance on reward signals rather than labeled examples presents another potential reduction in data engineering overhead. Instead of requiring extensive human annotation, RL systems learn from simple feedback signals that indicate the success or failure of actions. This fundamental shift can significantly reduce the traditional data preparation burden.
Leveraging Synthetic Environments

Many RL applications begin their training journey in simulated environments, providing a controlled and readily available data source. This approach can substantially reduce the initial data engineering requirements typically associated with real-world data collection and processing.
Lunar Landing Reinforcement Learning
One of the best ways to understand the amount of complexity necessary in order to train a reinforcement learning model is through this code, with these few lines of code, a lunar lander was able to learn how to land safely on its target position.
import gymnasium as gym
from stable_baselines3 import PPO
from stable_baselines3.common.env_util import make_vec_env
vec_env = make_vec_env("LunarLander-v3")
model = PPO("MlpPolicy", vec_env, verbose=1)
model.learn(total_timesteps=750000)
model.save("LunarLander-v3-750k-ts")
No Training

250k Timesteps Results

500k Timesteps Results

750k Timesteps Results

The Hidden Data Engineering Challenges
Complex Environment Engineering
While RL might reduce certain aspects of traditional data engineering, it introduces its own set of challenges. Creating and maintaining effective training environments requires sophisticated engineering work, including:
Designing accurate state representations
Defining appropriate action spaces
Crafting meaningful reward functions
Developing realistic simulators
Managing Interaction Histories
The need to store and process interaction histories introduces significant data management challenges. Each training episode generates sequences of state-action-reward tuples that must be efficiently stored, accessed, and analyzed. This becomes particularly demanding in applications with extended training periods or complex environmental interactions.
Specialized Data Pipeline Requirements
RL systems often require specialized data pipeline components to handle unique requirements such as:
Experience replay mechanisms for efficient learning
Data synchronization in distributed training setups
Storage and processing of historical policy data
Real-time monitoring and debugging capabilities
The Reality: Different Rather Than Less
The relationship between reinforcement learning and data engineering isn't about reduction, it's about transformation. While RL might minimize certain traditional data engineering tasks, it introduces new challenges that require equally sophisticated solutions.
Conclusion
While reinforcement learning offers exciting alternatives to traditional machine learning approaches, it doesn't eliminate the need for data engineering, it transforms it. Success in RL projects requires understanding and embracing these unique data engineering challenges rather than assuming they don't exist.
P.S. Let's Build Something Cool Together!
Drowning in data? Pipelines giving you a headache? I've been there – and I actually enjoy fixing these things. I'm that data engineer who: - Makes ETL pipelines behave - Turns data warehouse chaos into zen - Gets ML models from laptop to production.
If you find this blog interesting, connect with me on Linkedin and make sure to leave a message!